
(报告出品方:中信证券)
国产 GPU 发展窗口期已至,生态构筑核心优势
AI 发展已经带动 GPU 行业高速发展,国产 AI 也为国产 GPU 的发展提供契机。在国际供应链不确定性背景下,我们认为,未来三年可能是国产 GPU 发展的关键窗口期,这一段时期,国产 GPU 有望取得长足发展,有可能是较好的投资时期。目前,国内 GPU 领域公司数量较多,从性能指标方面来看,已有部分公司能够在理论硬件性能方面接近国际主流水平,理论算力指标较高。
同时,在芯片对外带宽方面,英伟达也并非完全高不可攀。例如,根据 AMD 官网,其 MI 系列产品的带宽就经历了快速进化,从 MI50 到 MI100 再到 MI250,其 Infinity Fabric 通道就从 2 个提升到 8 个,对外带宽从 184GB/s 提升到 800GB/s。国内产品在通信方面也进行了尝试,例如壁仞科技的 BR100 芯片,其 BLink 技术就实现了 8 通道,合计 512GB/s 的对外带宽,技术定位类似于英伟达的 NVLink。
但尽管国产芯片的理论算力和理论带宽均能够做到较为良好的水平,理论性能却往往面临软件生态的限制,即便集成 GPU 领域的领先企业 Intel 也无法摆脱这一规律。Intel 新发布的独显 Arc 系列在使用了更多晶体管的前提下,具备更高的理论性能,但实际使用性能相比友商的基础型显卡有一定差距。
我们从软件测试中可以看见,3Dmark 测试所代表的 GPU 理论性能测试中,Intel 的 Arc 系列均有亮眼表现,而到了实际使用场景中,Intel Arc 系列产品的实际帧率相比同样的友商产品则有一定差距,重要原因在于驱动程序,而驱动程序正是生态的核心组成部分之一。

另外生态在数据中心与开发者场景中起到更重要的作用,能够重塑整个数据科学/AI 工作流程,加强开发者黏性,形成正反馈。在开发者的日常流程中,首个环节是数据管理,包括数据从数据来源的提取(Extraction)、变形(Transform)、加载到应用端(Load), 合并称为 ETL,随后还有数据的存储等。其次是数据训练、验证(可视化)、部署(推理)等多个环节。足够良好的 GPU 生态能够极大影响上述工作流,首先可以将模型训练环节迁移到 GPU,随后还可以将 ETL 环节(传统上由 CPU 完成)也迁移到 GPU 上,让整个数据科学/AI 工作流几乎全部在 GPU 上完成。
通过发达的 GPU 软件支持实现工作流迁移,能够极大提高效率,从而重塑开发者的软件使用习惯,让开发者的黏性极大增加,形成正反馈,持续提高软件生态的壁垒。
形成上述正反馈的前提是在每个环节中都必须有足够丰富、可靠、易于使用的工具供开发者使用,且最好是开发者熟悉、拥有成熟社区的,由此可见生态的重要性。
CUDA:GPU 生态先驱,AI 时代基础设施
提及生态,GPU 生态的奠基者 CUDA 是无法绕过的。如今整个科学计算、AI 的软件生态大多构建在 CUDA 的基础之上。CUDA 也是软件生态的标杆,从软件库的覆盖面、AI 框架和算子库的支持程度两方面来讲,都是目前最完善的。
CUDA 的诞生:实现从 GPU 到 GPGPU 的转变。在 CUDA 问世之前,想要调用 GPU 的计算能力必须编写大量的底层语言代码或借用图形 API,对使用高级语言为主的程序员十分不便。英伟达公司的首席技术官 David Kirk 以及 CEO 黄仁勋主导推出了 CUDA。2006 年 CUDA 发布,2007 年正式推出 CUDA1.0 公测版本。此后程序员无需再通过图形 API 来调用 GPU,而是可以直接采用类似 C 语言的方式直接操控 GPU。2008-2010 年,CUDA 平台进一步发展,拓展了新局域的同步指令、扩充全速常量内存并且支持递归,NVIDIA 向各软件厂商免费提供开发工具,使得 CUDA 生态初具规模。
发展:十年苦坐冷板凳,与 AI 生态深度绑定。在 CUDA 系统诞生之初,英伟达大量投入研发对 CUDA 进行不断更新与维护,但并没有立即得到市场的认可,CUDA 用户不多但大量研发却直接影响利润,英伟达市值长期不振,直到 2016 年市值才超过 2007 年的水平。但 CUDA 对科学计算领域的渗透一直在进行,2012 年深度学习革命开始以来更是一直在渗透 AI 领域,2012 年 ImageNet 挑战赛冠军使用的就是英伟达 GTX580 GPU。此后 CUDA 持续迭代,2023 年 CUDA 已经推出最新的 12.0 版本 API。如今整个 HPC 与 AI 生态都已经与 CUDA 形成了深度绑定,CUDA 已经成功塑造了用户习惯,成为了 AI 时代开发者最熟悉的工具箱。
CUDA 生态:组件庞杂、取代难度高。CUDA 所包含的生态组分众多,包含编程语言和 API、开发库、分析和调试工具、数据中心和集群管理工具,以及 GPU 硬件等多个大类。每一大类中都包含了大量的组件,是英伟达以及开源生态开发者们在二十年间日积月累所形成,如今要将其取代难度较大,需要巨量的时间和资源投入。CUDA 生态虽已成为 AI 和 HPC 几乎不可分割的一部分,但英伟达占据了绝大部分市场份额,对下游用户来说,其使用成本也不低(根据英伟达财报,近 5 年来其毛利率基本维持在 60%上下),用户有意愿寻求低成本替代。且在当前国际局势下,中国本土企业面临一定的供应链不确定性。因此,对于诸多企业而言,在 CUDA 之外寻找一个第二选项,是对于企业经营可行的选择,要做到这一点,就需要尽可能跨越 CUDA 的护城河。
CUDA 的两大生态护城河:软件库覆盖率、AI 框架支持度。对于后来者而言,关键是采取切实可行的措施向 CUDA 学习靠拢,进行自身生态建设。我们认为,CUDA 的第一个壁垒是软件库覆盖率,既包含了基础的并行计算软件库,也包含了细分行业软件库,还有配套的辅助软件等;第二个壁垒则是针对 AI 领域而言的 AI 框架支持率。对于我国芯片公司而言,中短期内可以尽可能投入资源实现的是并行计算软件+辅助软件库开发,以及对 AI 框架的完善支持,而对于细分行业的支持,则需要较长的时间和积累。
并行计算软件库覆盖度:以 ROCm 为例
目前,有望替代 CUDA的选项已经存在,即 ROCm。ROCm 是 AMD 开发的对标 CUDA 的软件平台。ROCm 全称为 Radeon Open Computing platforM,是基于 AMD 系列 GPU 设计的开源计算生态,同时也能够相当大程度上兼容 CUDA、支持 NVIDIA GPU,其目标是建立有望替代 NVIDIA CUDA 生态的平台。
以下我们将以 ROCm 为例,分析生态的第一个核心要素——并行计算软件库覆盖度,包括软件支持覆盖范围的变化及其影响,未来的演变趋势等。
ROCm 前为何没有能挑战 CUDA 者?OpenCL 自身不足,AMD 旧产品性能待提升
ROCm 出现之前,AMD 也意识到 GPU 在 AI 计算领域的潜力。根据五二电子工作室网站信息,AMD 曾经尝试利用 OpenCL 打入深度计算领域,先是尝试移植 cuda-convnet,后转向 Caffe,最后的成果是 OpenCL Caffe,虽然是有益的尝试,但这项努力并没有引起很多的关注,其成果也局限在单一工具,并未构建起有效的平台。此前尝试失败的一个重要原因在于 AMD 此前一直使用 OpenCL,而 OpenCL 本身具有不足之处:语言支持少(2015 年以前只支持 C),更多面向底层软件而非上层软件。另外硬件层面,主导 ROCm 生态的 AMD 此前在计算卡系列仍然采用 GCN 架构,产品性能相对不足。
软件不足:OpenCL 对 HPC 支持有限,产品节奏长期滞后
OpenCL 最早提出是为了应对单核性能极限与多核并行计算的发展,最初由苹果开发,并与 AMD、Intel、英伟达、高通、IBM 的团队合作完成 API 方案,各家公司在 2008 年合作成立 Khronos 计算工作组,并于当年发布 OpenCL 标准,各公司采用统一的 API,但各自完成实现方式。需要注意的是,这时 GPU 的算力价值还没有被广泛认知,Khronos 成员除了英伟达外均以 CPU 为主业,OpenCL 也更多考虑了多核 CPU 计算,导致 OpenCL 更多考虑底层硬件驱动/操作系统支持,对高层的科学计算库等支持则相对有限。这一点从支持的语言也可以看出,OpenCL 长期以来仅支持 C 语言(底层驱动、操作系统等多使用 C),而科学计算库常用的 C++支持直到 2015 年的 OpenCL2.1 版本才得以推出。
与之相对比,英伟达早在 2010 年的 CUDA 3.0 版本就已经添加 C++和 Fortran 支持,2011 年的 4.0 版本更通过 GPU Direct 2.0 等技术在 HPC 领域站稳脚跟,2013 年的 GTC13 上,CUDA 添加了 Python 支持,易学易用水平再度提升,到 OpenCL 发布 C++支持的 2015 年,CUDA 已经迭代到 7.0 版本,形成了相对稳定的护城河。可见二者在科学计算领域的统治力完全不可同日而语。根据 AnandTech,OpenCL 始终没有在 HPC 领域获得大规模应用,遑论后续的 AI。
硬件不足:早期 MI 产品性能待提高,对数据中心用户吸引力有限
ROCm 诞生前以及诞生早期,CUDA 以外的计算生态推广也有硬件方面的原因。如果仅是软件支持不足,那么如果硬件性能占优或具备明显的性价比优势,硬件产品仍然有可能在一些对生态要求不高的细分领域得到销售,例如虚拟货币市场,AMD 桌面显卡曾经依靠较高的浮点性能占据较高的份额。

但根据AMD官网发布的信息可以看到,早期AMD的计算卡在性能表现方面并不占优。在 2020 年 CDNA 架构面世前,AMD 的数据中心 GPU 一直使用的是 GCN 系列架构,搭载 GCN 系列架构的产品在 2012 年就已推出,虽然在游戏机等场景获得较高市场份额,但在数据中心市场并未取得显著成果,这与其性能表现有关。AMD 在 2017 和 2018 年曾经两次推出 Instinct MI 系列数据中心 GPU,但第一批推出的 MI6、MI8、MI25 在算力表现上与同期的 NVIDIA V100 具有一定差距,这三款 GPU 的 FP64 算力均未超过 1TFLOPS,而 V100 的两个版本均在 7TFLOPS 以上,FP32 算力也仅采用 GCN5 架构的 MI25 与 V100 相对接近。到了 2018Q4 批次推出的 MI50/MI60,AMD 终于在算力表现上接近 2017 年推出的 V100。
而在显存与带宽等方面,2017 年批次的 MI 系列显存容量与带宽仅有 V100 的约一半水平,而 GPU 互联方面尚未配备 Infinity Fabric,带宽与 V100 SXM 的 NVLink 也有差距。到 2018Q4 批次的 MI50/MI60,AMD 为其配备了初代 Infinity Fabric,单通道 92GB/s,共计双通道 184GB/s,有所提升,在显存与外部带宽方面向 V100 靠拢。
从上述性能对比可见,早期的 Instinct MI 系列 GPU 性能与 V100 相比仍有差距,也在一定程度上影响了 ROCm 生态的推广。这一现象随着 AMD CDNA 架构的推出有所改观,2020 年 Q4,MI100 与 NVIDIAA100 在相近的时间推出,其 FP64、TF64、FP32 算力指标全面超越 A100,但在 AI 常用的低精度张量计算(TF32、TF16、INT8 等)方面仍与 A100 存在较大的算力差距。到了 CDNA 这一代,AMD 在数据中心 GPU 硬件算力方面可以说已经与 NVIDIA 互有优劣,不再是被全方位包围的态势。到了 CDNA2 这一代,MI 250/250X 在 FP64、TF64、FP16 计算方面取得了相对 H100 的优势,但 FP32、TF32、TF16 算力方面弱于 H100,在张量计算方面仍然不及 NVIDIA,但可以说维持住了与 NVIDIA 主力产品各有优势的局面。
显存方面,MI250/MI250X 在容量与带宽方面超越了 H100 SXM 版本。在外部带宽方面也凭借 8 通道 Infinity Fabric 实现了 800GB/s 的带宽,接近 H100 SXM 的 900GB/s。
综上所述,ROCm 的推广缓慢受到硬件性能发展滞后的影响,但硬件方面的掣肘随着 2020 年 CDNA 架构产品的发布已经有所改善,在可见的未来,硬件方面可能不再对 ROCm 构成限制。
AMD 系算力走向实用化的转折点:重建基础平台,从 OpenCL 转向 HIP
OpenCL 的发展迟缓导致了 AMD 多年未能在 GPU 计算领域有所作为,更多局限在游戏卡领域,而神经网络、区块链等技术在 2010s 的发展让英伟达获取了大量市场份额,CUDA 生态的护城河愈发强大。AMD 也希望能够改变自身市场地位,因而进行了完全的战略转向,不再基于 OpenCL 仅仅提供单体工具,而是开始全面拥抱现有 CUDA 生态, 并构造软件平台,实现开发者的低成本迁移,这一过程持续至今,并且在可见的未来仍将持续。
具体而言,AMD 首先在 2015 年 11 月的 SC15 超算会议上提出 Boltzman 计划(得名于奥地利物理学家玻尔兹曼,其在统计物理学领域的成果对科学计算中的流体模拟、AI 中的随机 RNN 等都有重要作用)。Boltzman 计划的主要内容在于将标准 C++引入 AMD 计算生态,并为其提供 HCC 编译器(Heterogeneous Compute Compiler,对标英伟达 NVCC),同时提供HIP(Heterogeneous-compute Interface for Portability)套装来拥抱现有的 CUDA 生态。
AMD 官方对于这一战略也赋予了较高期待,希望能够给 GPU 计算生态带来变化,这从 AMD 在玻尔兹曼计划开始一年后的 SC16 大会上的相关表态可以得以体现。
落实到具体执行层面,如何真正在 GPU 生态立足?我们认为,第一要与 CUDA 生态融合,做到低成本迁移;第二要在保证可迁移性的前提下优化体验,追求更广的函数库覆盖、更佳的易用性以及性能;第三需要有足够的迭代速度,才能在市场上形成正循环。以下我们分别对这几方面进行分析。
ROCm 如何融入 CUDA 生态:HIP 通用前端代码+Hipify 转换工具
ROCm 首先需要融入 CUDA 生态,这一点主要通过 HIP 系列函数库完成。具体而言有两种兼容方式,第一种针对存量程序,即将已有的 CUDA 代码运行在 AMD 或类似的 GPU 上,这一方式可以通过 Hipify 工具来实现,将 CUDA 代码转化为等效的 HIP 代码,再经过 ROCm 的编译器,即可运行;第二种针对增量程序,即希望新写的代码能够同时 在 NVIDIA 或 AMD 的 GPU 上运行,这一方式较为简单,HIP 代码通常扮演与用户交互的“前端”角色,而真正执行任务的“后端”既可以是 ROCm 生态的各种 roc 开头的函数库,也可以是 CUDA 生态的 cu 开头的函数库,可以由 HIP 函数库在运行时自动检测、自动选择,所以 HIP 代码可以一次写作多平台部署。
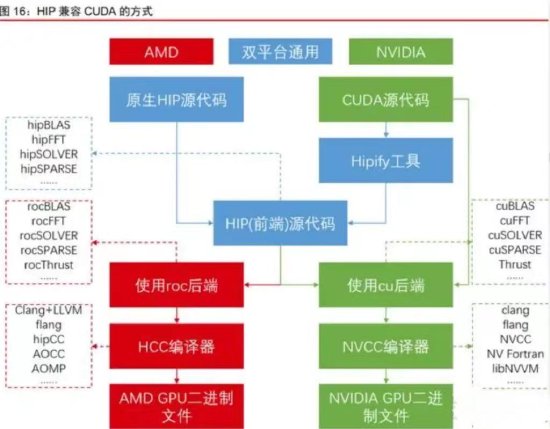
此处一个值得注意的点在于,Hipify 工具是否能够真正实现 CUDA 代码的完美转换?ROCm 生态中提供了两种 Hipify 工具,第一种是一个编译器,将 CUDA 代码编译成 HIP 代码,采用的是目前较为成熟的 clang 编译器前端,只要 CUDA 代码正确、引入的外部信息均可获得,那么代码就能够得到妥善翻译;第二种是一个简单的脚本,采用 Perl 语言,其功能就是文本替换,按照一定规则将 CUDA 代码中的各种函数名称替换成 HIP 中的对应函数,但这个脚本在面对较为复杂的代码结构时有一定局限性。
由上述内容可见,如今的 ROCm 在融入 CUDA 生态方面基本具备一定能力。
ROCm 可以多大程度上替代 CUDA:支持日渐完整,体验仍需进步
在能够基本融入 CUDA 生态的基础上,接下来的问题就在于使用体验。具体而言,可以分为软件库支持、基础软硬件硬件支持、性能、易用性等方面。
软件库支持:支持范围持续扩大,基本支持 AI 与 HPC 生态
软件库支持是可用性的核心,2015 年以来 ROCm 生态持续丰富组件。2016 年,ROCm1.0 阶段,基本的数据格式、基本运算指令、常用的基础线性代数库、部分常用 AI 框架已经得到初步支持
在随后的年份中,ROCm 生态继续得到优化,2018 年开始开发容器支持以及系统管理工具;2019 年 ROCm3.0 版本中基本将系统/集群管理工具、集群通信工具、容器工具开发完成,AI 框架支持基本实现;2020 年 ROCm4.0 版本中,HPC 生态已实现初步可用,各类核心基础库基本完成初步搭建。
此后 ROCm 也持续更新到 2023 年 4 月已经推出 ROCm5.6 版本,形成了底层驱动/运行时、编程模型、编译器与测试调试工具、计算库、部署工具等相对清晰的软件架构。
在当前 AI 领域最常用的 AI 框架与并行计算算法库方面,ROCm 5.0 及以后的框架始终保持着紧密跟踪支持,为其在 AI 领域渗透提供了基础。
目前从完成度上来看,ROCm 对比 CUDA 已经在开发、分析工具、基础运算库、深度学习库与框架、系统软件方面做到相对完整的支持,但对于 DPU、物理模拟、细分领域、用户界面等支持还存在一定不足,例如用于 GIS 和空间运算的 cuSpatial、用于产生 GUI 的 cuxfilter、用于材料物理模拟的 Modulus 等,ROCm 尚未在这些领域提供完善的支持。
基础软硬件支持:Windows 支持或将面世,CDNA 与 RDNA 架构支持提升
仅支持 AI 的核心框架与算法库对于 GPU 而言仍然不够,往往需要全面的软硬件支持才能触及大量用户,在使用中获得反馈、进行快速迭代,从而构建生态护城河。操作系统方面,目前 ROCm 的现状仍以支持 Linux 为主,未来计划添加 Windows 支持。当前版本 ROCm 支持的操作系统主要是 3 类 Linux 发行版:RHEL(Red Hat Enterprise Linux)、SLES(SUSE Linux Enterprise Server)、Ubuntu。
对 Windows 的官方支持不足是 ROCm 目前的一个短板,而早在 2007 年的 CUDA 1.0 时代,CUDA 就已经明确支持 Windows,这也让 CUDA 的用户群体更加广泛。
但面对 CUDA 的优势,ROCm 也在跟进,根据 AnandTech 的文章,尽管 AMD 尽量避免对 Windows 支持上线日期做出承诺,但其工作日志显示 AMD 仍在进行 Windows 方面的开发。
硬件支持方面,目前 ROCm 支持的 GPU 型号主要集中在计算卡领域,图形卡的 ROCm 支持已经有所进步但仍需扩展。目前 Instinct 计算卡方面,从 MI50(GCN5.1 架构)以后(CDNA 系列架构)均实现了 ROCm 完整支持(仅需使用 ROCm 自带的驱动),但只能在 Linux 环境下使用。
专业图形显卡方面,目前支持的型号还较为有限,在使用 Radeon Pro 驱动的情况下,部分基于 GCN5.1 架构以及 RDNA/RDNA2 架构的专业显卡(用于工作站等场景的 Radeon Pro 系列)也进行了适配,其中 Radeon Pro W6800 实现了 Windows 支持,其余诸如 W6600、W5000 系列等型号并未在文档中提及。
图形卡/游戏卡方面,目前支持的型号也较为有限,官方提供完整支持的仅有 Radeon VII,另有 RX6600 获得了 HIP Runtime 在 Linux/Windows 的支持,RX6900XT 获得了 HIP SDK(包含 HIP Runtime 以及一组 GPU 计算库)在 Linux/Windows 的支持,其余绝大多数普通游戏卡并未在文档支持列表中被提及。据快科技和 AnandTech 消息,2023Q3 版本的 ROCm 有望首次支持 RDNA3 架构,包括 Radeon Pro W7900 48GB 专业显卡、Radeon RX 7900 XTX 24GB 游戏显卡等。
与之相比,NVIDIA 目前全产品线支持 CUDA,能够获得更广阔的市场空间。尤其是对于图像生成等算力消耗较小的应用,用户往往只需购买一张 NVIDIA 游戏卡,并在 CUDA 支持下进行部署即可,这一张游戏卡还能支持其他日常工作与娱乐,对于小用户具有较强的吸引力。而同样的工作(Stable Diffusion),在 ROCm 生态内部,现在是由开源社区自发支持的(docker_sd_webui_gfx1100 项目)。硬件支持还包括 CPU 方面,目前只需 Intel Haswell 架构(2013 年)以后或 AMD Zen 架构以后的产品即可。虚拟化支持对于数据中心给客户按需分配算力较为重要,目前 ROCm 生态在此处的支持水平尚可,已经能够支持 VMWare ESXi 7/8 版本。
综合来看,ROCm 生态在软硬件支持领域目前已经有一定可用性,但 Windows 支持和 GPU 产品的全线支持仍需继续推进。
性能表现与易用性:ROCm 在 AI 框架领域性能无短板,易用性尚需提升
软硬件与库决定可用范围,而在可用范围内更多比较的是优化水平(性能水平)与易用性。性能层面,在进行了完善优化的情况下,ROCm 与 CUDA 的差距并不大。以 Pytorch 为例,Meta 与北卡州立大学的研究人员进行了较为全面的测试,使用 NVIDIAA100 与 AMD MI210 测试模型运行所需时间,如果比值小于 1 则说明模型在 A100 上表现更佳,反之则说明在 MI210 上表现更佳。研究人员得出结论,最终模型运行的时间表现与 Tensor Core 有关,如果模型能够使用 Tensor Core 的部分更多,则通常在 A100 上的表现更好。
但并非所有模型都能使用 TF32 数据格式,如果模型使用了更多的“按对应位置的运算”(在两个矩阵中位于相同位置的元素进行加减乘除),那么就无法调用 Tensor Core,此时 MI200 FP32 算力更高的优势就能够得以体现。同时,按照训练和推理分类页可见,在大多数推理场景中 A100 性能更好,因为推理场景中使用 Tensor Core 的比例更高。
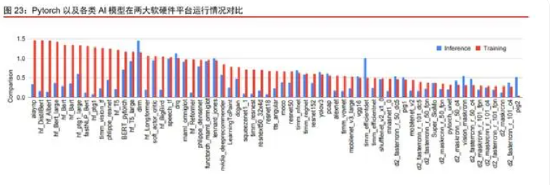
通过上述研究结果可见,Pytorch 模型性能基本准确反映了 A100 与 MI210 的性能区别,从而也说明 ROCm 在支持完善的框架领域相比 CUDA 并无明显性能损失。
易用性方面,对于个人用户而言,ROCm 与 CUDA 相比还存在一定差距。目前 CUDA Toolkit 已经可以在英伟达官网直接下载安装包,如同其他应用程序一样快速安装完成。
如果要在 CUDA Toolkit 的基础上添加功能,例如添加深度学习功能,只需在官网下载 cuDNN 对应的 zip 压缩包(或其他格式压缩包)并解压即可,其内部就包含了所需使用的 C 语言头文件、动态链接库、lib 文件等,操作十分简便。
与之对比,ROCm 由于只支持 Linux,其使用命令行形式或脚本形式安装门槛比 CUDA 的图形化操作要更高,对于开发人员或算法工程师等专业人士尚可,但对于并非以 AI 为核心专业的用户仍有一定门槛。
总结:张量计算待提升,基础软硬件与软件库支持需完善
综上所述,ROCm 生态已经能够一定程度上对 CUDA 进行替代,尤其在核心的 AI 领域已经具备较为完善的支持和可用性,但要更进一步仍需利用 AMD 以及开源社区的力量,对张量算力、易用性、Windows 支持、硬件支持范围等方面进行优化。
ROCm 的未来:开源是后发者的合理选择,或可参照 Python 与 MATLAB
综上所述,如今的 ROCm 已经逐渐具备了枝干,仍待枝繁叶茂。为了在整体研发投入不及 CUDA 的情况下让后发者的生态逐步茂盛,开源并借助外界的社区力量是一个可行的选择。目前整个 ROCm 项目的源代码基本已经全部公布于 GitHub,在众多组件当中,只有 AMD 私有的编译器 AOCC(在开源 LLVM 的基础上修改而来,针对 AMD 硬件进行优化)属于闭源项目,其余均通过不同形式的开源许可证进行开源,整个开源社区的开发者力量均可为 ROCm 项目的完善做出贡献。
开源是否能真正促进生态的完善甚至帮助 ROCm 超越 CUDA?这一问题的答案并不是非黑即白,开源能够聚集社区开发力量,而商业闭环则能够实现有效的经济激励,可谓各有优势。但对于处在后发位置的 ROCm 来说,采用开源模式或许更为合适。其原因在于,商业闭环的能量与商业生态的规模直接相关,如果 ROCm 与 CUDA 同样闭源,则受 限于收入与利润规模,AMD 的研发资源大概率不如 NVIDIA 多,难以取得竞争优势。
那么如何对趋势进行更具体的判断?可以参考以往的案例,例如 iOS/Android、Windows/Linux、MATLAB/Python 等。其中前两对都是操作系统,用户群体较为广泛,生态的力量也强大很多;或许更可以类比的是 Python 与 MATLAB,二者同为编程语言,各有自身的生态,用户都是软件开发者或科学计算等领域的专业人士,其生态的强度或许与 ROCm/CUDA 更为接近,且软件生态的构成也都是中心化的常规软件库与细分专业库相结合,因此在生态构成方面也具有较高的可比性。
Python 作为开源的代表,凭借开源能够获取相当大一部分市场。由于其简洁易用免费的特性已经成为 AI 和数据科学领域首选语言,根据 TIOBE 的统计,Python 语言的市占率近年来快速上升,屡居第一,达到 15%左右。目前 AI 领域的 Pytorch、TensorFlow 以及数据处理领域的pandas以及各类爬虫库乃至金融科技等领域均有大量 Python 库在生态中居于领先地位。这与生态规模相对较大、需求相似度高、可标准化程度高有关,投入产出比较高,因此能够聚集足够多的开发者,迅速建立起足够强大的生态,并凭借开源免费易用的优势牢牢把持优势地位。
而 MATLAB 则凭借全面优质的 simulink 支持,把控大多数细分场景。在各种电力、机械仿真模拟等领域,simulink 依靠商业循环推出了大量工具箱,完成了大量细分领域的覆盖与支持,并形成较强的用户粘性。这些领域由于用户规模较少,且用户大多不是专业的程序开发人员,往往生态形成速度较慢,MATLAB 能够以此在相当长的时间内维持相对稳定的市场地位。
因此我们认为,在长期来看,ROCm 生态有望凭借开源的特性,在一些较大的生态领域(如 AI 领域)迅速形成软件的全面覆盖,逐步占据更多份额,至于一些较为细分的领域(如材料物理模拟等),ROCm 或许还需要更长的时间才能具备竞争力。
AI 框架支持:以昇腾为例,算法库+配套软件基建
对于 GPU/GPGPU 而言,通用并行算法(通常为向量计算)的广泛支持是软件生态的核心优势,然而对于 AI 芯片(NPU 等)而言,其本身的硬件架构(专注强化矩阵计算,而矩阵计算单元并不能进行向量运算)决定了其难以真正全面支持并行计算需求。因此,对于此类芯片,重点在于实现 AI 框架支持,发挥其在 AI 领域的高效性。以 NPU 领域较为领先的华为昇腾为例。其采用自主开发的 CANN 软件体系,适配的计算库主要是神经网络(Neural Network,NN)库、线性代数计算库(Basic Linear Algebra Subprograms,BLAS),这两类库以矩阵类运算为主,与其硬件架构相合,而其余常规的向量计算库,支持则并不十分完备。
尽管全面支持通用并行计算有一定困难,但如果将适用领域局限在 AI 范围,NPU 仍然可以提供相对完善的支持,其主要原因在于大多数 AI 程序都利用了成熟的 AI 框架,如果能对 AI 框架提供足够完善的支持,则仍然是在 AI 领域的可用选择。当前在诸多 AI 框架中,全球使用率最高的当属 Pytorch,随后是 TensorFlow 等。据 AssemblyAI 等数据,当前 GitHub 新 AI 项目当中,有近 70%使用的 AI 框架是 Pytorch;在 HuggingFace 平台上最受欢迎的 30 个模型当中,有 7 个仅使用 Pytorch,23 个同时支持 Pytorch 和 TensorFlow。
从 AI 框架的使用情况可见,对于 AI 芯片的生态构建,并行计算库的全面覆盖并非唯一路径,实现对 AI 框架的良好支持是另一条路径。能够完善支持 Pytorch、TensorFlow 等,即可满足相当一部分 AI 需求。当前国内已有 AI 芯片在此方面取得显著进步,举例来说,昇腾 CANN 提供 AI 框架适配器 Framework Adaptor 用于兼容 Tensorflow、Pytorch 等主流 AI 框架。华为昇腾 NPU 团队通过长期投入适配工作,已于 2023 年 10 月 4 日的 Pytorch2.1 版本中被纳入第三方设备原生支持列表,在国内进度领先,有望借此形成生态优势并保持。
但将适配工作拆开来看,要实现 AI 框架的完善支持,其工作量仍然较大,核心工作之一就是实现算子库的支持,各家的实际支持度不一定完全相同。所谓算子即实现特定功能的运算操作。对于通常的 AI 框架来说,其所需支持的算子数量较为庞大,因此需要大量资源和时间进行软件支持。考虑到 Pytorch 自定义算子较多,支持的操作较为庞杂,因此我们可以在其他 AI 框架中大致了解算子库的内容。比如 ONNX 框架,其中包含了上百种不同的计算操作,硬件开发商需在其硬件指令集的基础上实现诸多算子,其中不乏相对复杂的算子。map、reduce 等经典的大数据处理操作、分类器常用的 OneHot 编码、各类激活函数、超越函数等都包括在内。
参考前文 AMD 的相关历史,ROCm 对各类算子和工具库的初步适配经过了约 3-5 年时间,与昇腾从 2019 年发布到 2023 年获得原生支持经过的时间类似。在这样的资源与工作量投入下,昇腾才得以在国内 NPU 芯片领域占据强势地位,根据昇腾官网 ModelZoo 页面显示,其提供的神经网络模型样例有 200 余个,涵盖了视觉的分割、分类、生成,语音和声纹识别,NLP、机器翻译、推荐系统、LLM、扩散模型、多模态模型等类型,下载量靠前的包括了 YOLO、BERT、ChatGLM、ResNet、LLaMA 等经典模型。
国内厂商生态进展:或复刻 CUDA,或兼容框架
目前国产 GPU 公司均在通过不同方式对 CUDA 进行兼容,提高各类计算库的覆盖率,同时实现对AI框架的支持。而 AI 芯片产品由于硬件架构限制,往往不一定追求兼容CUDA,而是尝试通过增加自行开发的方式,直接与 AI 框架进行兼容。GPU 方面,各公司的软件生态架构、兼容 CUDA 的思路大多与 ROCm 类似。例如摩尔线程官网显示,其自主构建了 MUSA 生态来兼容 CUDA,其生态组成与英伟达 CUDA 极为接近,基本所有组件都有与 CUDA 的对应关系,例如采用 muDNN 代替 cuDNN、muBLAS 代替 cuBLAS 等,另外自行开发 MCC 编译器等。
根据摩尔线程官网显示,摩尔线程兼容 CUDA 的手段与 ROCm 是基本一致的,可以通过 MUSIFY 工具将 CUDA 代码迁移到 MUSA 平台,正如 ROCm 生态中的 Hipify;通过自行实现 MUSA-X 计算库(类似 rocBLAS、rocFFT 等),来实现 CUDA API 的一对一替换;通过 MUSA Toolkit 来进行编译、调用 MUSA 程序后端,实现 CUDA 代码兼容。
但 MUSA 生态与 ROCm 的不同在于,MUSA 的大部分组件并不开源。在摩尔线程的 GitHub 官方页面可见,其名下仅有 3 个开源库,其中 qtbase 和 installer-framework 均与可视化界面有关,仅有 torch_musa 库与实际的运算有关,用来兼容 Pytorch。而其中,Qt 本身属于开源项目,Pytorch 作为基于 Python 的项目,同样也是开源的,可见 MUSA 生态除开源社区项目外均采用闭源方式构建。这一方式的弊端在于,摩尔线程作为创业公司,其资源未必能与 AMD 等成熟大型公司相当,构建生态、形成规模效应的难度更大,在 GPU 生态的竞争中取得先发优势也更困难。
与之类似,壁仞科技也开发了 BIRENSUPA 平台试图兼容 CUDA,但并非开源项目,需要自行构建各类计算库与工具,也同样受到资源限制。
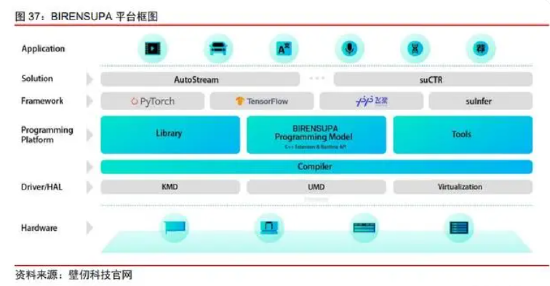
目前从结果来看,其生态构建确实也需要进一步推进。除了自身开发的 BRCC 编译器外,还需要自行开发设备端以及主机上的各类驱动/运行时程序,以及基础的测试和管理程序。其当前计算库主要包含 DL 算子库、并行计算库、多卡通讯库等基础库,应用端主要有两大行业解决方案,分别是负责视频分析的 AutoStream 和负责广告推荐系统的 suCTR,目前覆盖的范围还有限。我们认为其软件生态覆盖水平约与 ROCm 早期版本类似。
沐曦集成电路的 MXMACA 平台也属于同一类型,通过自行开发 BLAS、DNN 等库,以及自行开发 Pytorch 等框架的兼容程序,来实现与 CUDA 生态的兼容。
此外还有天数智芯等厂商也提供其 GPU 产品以及 DeepSpark 开源软件生态,与其他 GPU 厂商一样支持 FFT 等 HPC 负载以及 AI 框架、辅助软件工具。
海光与上述同业企业在软件生态领域的一个主要区别在于充分利用开源社区,且兼容现有的国际主流开源方案,这也是我们认为海光相对容易进行 CUDA 软件生态替代的原因。从海光信息官网可见,目前海光使用的 MIOpen、RCCL、hipSPARSE 等库都属于国际主流开源社区,且在开源领域属于影响力较大的方案,这极大降低了海光自身开发软件生态的门槛。另外利用开源社区的好处在于代码公开,用户可以按需进行代码更改,这对于一个尚未完善的生态而言,也具有一定的作用。
NPU 方面,寒武纪的路线与昇腾类似。寒武纪基础软件平台是寒武纪专门针对其云、边、端的智能处理器产品打造的软件开发平台。其采用云边端一体、训推一体架构,可同时支持寒武纪云、边、端的全系列产品。寒武纪终端 IP、边缘端芯片、云端芯片共享同样的软件接口和完备生态,可以方便地进行智能应用的开发、迁移和调优。
寒武纪训练软件平台支持基于主流开源框架原生分布式通信方式,同时也支持 Horovod 开源分布式通信框架,可实现从单卡到集群的分布式训练任务(Horovod 是 Uber 开源的分布式训练框架,可以在对单机训练程序尽量少改动前提下进行并行训练,支持不同的前端训练框架和底层通信库,包括英伟达的 NCCL 以及 Intel 的 oneCCL,此处还包括寒武纪自身的 CNCL)。支持多种网络拓扑组织方式,并完整支持数据并行、模型并行和混合并行的训练方法。训练软件平台支持丰富的图形图像、语音、推荐以及 NLP 训练任务。通过底层算子库 CNNL 和通信库 CNCL,在实际训练业务中达到业界领先的硬件计算效率和通信效率。同时提供模型快速迁移方法,帮助用户快速完成现有业务模型的迁移。 MagicMind 是寒武纪全新打造的推理加速引擎,也是业界首个基于 MLIR 图编译技术达到商业化部署能力的推理引擎。借助 MagicMind,用户仅需投入极少的开发成本,即可将推理业务部署到寒武纪全系列产品上,并获得颇具竞争力的性能。
燧原科技作为国内 AI 芯片厂商也推出了自己的“驭算 TopsRider”生态框架,支持 AI 训练和推理,并对主流 AI 框架进行了支持。
总体来说,国产算力芯片在并行计算库、AI 框架领域都已经有所储备,但不同厂商的具体适配进度或存在一定差别。
我们认为软件生态是算力芯片可用性的核心,用户的学习成本决定了市面上难以长期同时存在大量的生态(尤其是 GPU 生态),且生态存在较强的正反馈特性,容易存在强者恒强,快者恒快的现象。而开源模式能够让公司调动超越自身规模的资源,加速生态发展,在生态竞争中占据先机。
来源:未来智库

0