
(报告出品方/作者:国盛证券,宋嘉吉、孙爽)
1 文生视频,多模态 AIGC 圣杯
文生视频当前处于起步阶段,随着文生图、图片对话技术的成熟,文生视频成为多模态 大模型下一步发展的重点。目前国内亦有文生视频功能,但主要停留在图片组合阶段。 我们认为,多模态,尤其是文生视频的发展将为应用的爆发提供更立体的基础设施,同 时对算力的需求也将指数级增长,对 AI 下阶段的发展至关重要。本文所介绍的文生视 频是指内容之间有关联性与协同性,能生成有连续逻辑的视频模型。
1.1 相较于文字和图片,视频能承载的信息量更大
相较于文字和图片,视频在多维信息表达、画面丰富性及动态性方面有更大优势。视频 可以结合文本、图像、声音及视觉效果,在单一媒体中融合多种信息形式。 从视频生视频到文生视频、图生视频,多模态的发展重视用更少的用户输入信息量实 现更丰富的 AI 生成结果。自 Runway推出Gen-1 视频生视频工具后,AI 处理视频、图 片功能在社交平台爆火,其背后即是多模态大模型发展的表现之一。在多模态应用方面, 当前可应用的模态转化主要集中在文字、图片、视频的转化。
1.2 当前公测的文生视频应用数量较少
文生图领域,2021 年 1 月 5 日,Open AI 发布其首个基于 Clip 模型的文生图模型 DALL·E,但并未开源,自此众多公司争先研发文生图模型;2022 年 3 月 13 日, Midjourney 发布可公测的文生图模型,其效果优越,引发了公众关于 AI 艺术的讨 论。目前已积累较多用户、可稳定使用的文生图模型主要有 Midjourney、Stable Diffusion、DALL·E 等。 文生视频领域,目前公众可使用的主要有 Runway Gen-1、Runway Gen-2、 ZeroScope、Pika Labs。其中,除 Runway 收费外,ZeroScope、Pika Labs 均可免 费使用。 文生视频发展速度慢于文生视频,在视频质量、视频时长等方面突破较为困难,相比于 文生图的快速优化迭代,文生视频的进展较慢。
即便是 Meta 和 Google 这样的硅谷人工智能巨头,在文生视频方面也进展缓慢。她们分别推出的 Make-A-Video 和 Phenaki 均尚未公测,从官方公布的 Demo 看,Phenaki 虽然 可生成任意长度视频,但其质量较差且欠缺真实性;Make-A-Video 无需“文本-视频” 配对数据集,视频质量相对较好,但时长短。
1.3 文生视频,难在哪里?
文生视频更困难。
技术实现本身更困难。从本质看,视频是连续的多帧图像,然而文生图到文 生视频并非简单的图片组合,而文生视频在文生图的基础上增加了时间维度。 文生视频需突破瓶颈多。可用的文生视频需具备一定的时长,优良的画面质 量,一定的创意逻辑性及还原指令要求能力。
计算难度大
计算成本高。通过文本生成高质量图片对算力的要求已经达到了一定程度, 由于生成视频模型复杂度提升及其时长、分辨率提高等因素,文生视频对算 力的需求进一步加大。 计算复杂性提升。文生视频需要进行高维特征融合,模型复杂度显著提升。
数据要求高
缺乏高质量配对数据集。视频的合理性及连贯性体现模型的架构能力、创造 力、理解能力。例如,当用户输入“一只大象在厨房做饭”这类文字指令时, 模型需理解文字指令内容,并根据训练数据库选取画面及对象组合,过程中 可能出现缺乏相应素材、难以合理组合人物、难以合理架构场景等问题。文 生视频需要大量的文本-视频配对数据,但当前缺乏相应数据集,数据标注工 作量极高。 缺乏具备多样性的数据集。由于用户的文本指令要求各异,缺乏多样数据集 使得模型无法生成预期效果。
技术融合难度大
多领域融合技术复杂性提升。文生视频涉及自然语言处理、视觉处理、画面 合成等领域,跨学科多领域使其需攻克的技术难点增加。
2 技术路线沿革:文生视频,哪种技术更强?
同文生图及大语言模型的发展类似,文生视频也在不断探索中寻找更为高效且效果更佳 的基础模型。目前主流的文生视频模型主要依托 Transformer 模型和扩散模型。 目前阿里 Model Scope 社区中提供了可用的、基于扩散模型的开源文生视频模型,促进 了如 ZeroScope 高质量文生视频模型的发展,有利于后续文生视频的技术迭代优化。
2.1 阶段一:基于 GAN 和 VAE,以 Text2Filter 为代表
原理:文生视频发展早期主要基于 GAN(Generative Adversarial Nets,生成式对 抗网络)和 VAE(Variational autoencoder,变分自编码器)进行视频生成。 GAN 由生成器和判别器构成,生成器类似于小偷,生成器生成图片;判别器 类似于警察,负责判断是生成器生成图片还是真实图片。 VAE由编码器及解码器构成,其使得图片能够编码成易于表示的形态,并且这 一形态能够尽可能无损地解码回原真实图像。 生成过程分为两步:首先,利用条件 VAE 模型从文本中提取出要点,即静态 和通用的特征,生成视频的基本背景;再借助 GAN 框架中的神经网络生成视 频细节。 问题:应用范围窄;仅适用静态、单一画面;分辨率低。 代表:Text2Filter。
2.2 阶段二:基于 Transformer,以 Phenaki 为代表
原理:Transformer 模型在文本及图像生成中均得到了广泛应用,因此也成为文生 视频使用较多的框架之一,但各模型在具体应用上仍有差别。主要思路即输入文 本后利用 Transformer 模型编码,将文本转化为视频令牌,进行特征融合后输出视 频。 问题:训练成本高;对配对数据集需求大。 代表:Phenaki、Cog Video、VideoGPT。 Phenaki 是基于 Transformer 框架进行文生视频的代表之一,其突破了文生视频的时 长限制进行任意时长视频生成。Phenaki 模型基于 1.4s 左右的短视频进行训练,通过连续的文字指令生成连续的较短时长的视频并串联成 1 分钟左右的长视频。例如,通过输 入一段类似故事的文字指令,从而实现逐个短视频的衔接成为长视频。
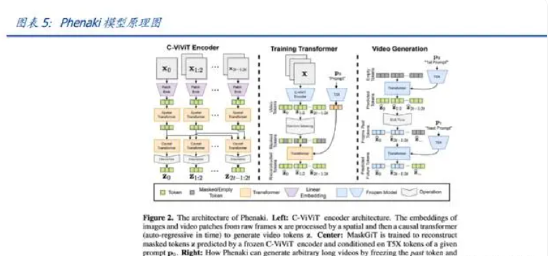
2.3 阶段三:基于扩散模型,以 Make-A-Video 和阿里通义为代表
原理:当前扩散模型是文生视频领域使用更广的架构之一。通过预训练模型进行 文本特征提取后,再进行文本到图片,图片到视频的生成,过程中需基于扩散模 型进行。简单来说,扩散模型即在图片上逐渐添加高斯噪声再进行反向操作。以 扩散模型为基础的文生视频模型,一般是在文生图基础上增加时间维度实现视频 生成。扩散模型在语义理解、内容丰富性上更有优势。 问题:耗时长。 代表:Make-A-Video、Video LDM、Text2Video-Zero、Runway-Gen1、RunwayGen2 以及 NUWA-XL。
2.3.1 Meta:Make-A-Video
Make-A-Video 是基于扩散模型的代表之一,其重点在于提升视频品质。其模型训练 时间较短,无需“文本-视频”配对数据即可生成视频。Make-A-Video 生成视频主要思 路为首先接受文字指令,后利用 CLIP 文字解码将其转化为向量;接着先验网络将 CLIP 文本向量“翻译”到对应的 CLIP 图像向量;后利用 Base Diffusion Model(一种文生图 的模型)生成视频的基本框架;此处得到额外的卷积层和注意力层到时间维度;后利用 Temporal Super-Resolution(TSR)进行帧插值以补充关键细节,最后利用两个空间超 分辨率模型升级各个帧的分辨率。
2.3.2 阿里达摩院:通义文生视频大模型
通义-文本生成视频大模型-英文-通用领域-v1.0 是由阿里达摩院提供的、发布在阿里 Model Scope 平台上的开源文生视频大模型,目前仍在集成中,暂未开放公测。通义文本生成视频大模型仅支持英文输入,基于多阶段文本到视频生成扩散模型。根据 Model Scope 官网,该模型整体参数约 60 亿,由五个子网格构成:文本特征提取:利用图文预训练模型 CLIP ViT-L/14@336px 的 text encoder 来提取 文本特征。 文本到图像特征扩散模型:Diffusion prior 部分,以 CLIP text embedding 为条件, 输出 CLIP image embedding。 图像特征到 64x64 视频生成模型:同样采用 diffusion model,以 GLIDE 模型中 UNet 结构为基础改造 UNet3D 结构,采用 cross attention 实现 image embedding 嵌入,输出 16x64x64 视频。 视频插帧扩散模型(16X64x64 到 64X64x64):diffusion 插帧模型,输入包括 16x64x64 视频、image embedding,输出 64X64x64 视频,其中 16x64x64 视频复 制 4 次到 64X64x64 以 concat 形式输入、image embedding 同样以 cross attention 形式嵌入。 视频超分扩散模型(64X64x64 到 64X256x256):diffusion 超分模型,同样为 UNet3D 结构,推理过程输入 64X64x64 视频,输出 64X256x256 视频。
2.3.3Zeroscope:由阿里达摩院 Model Scope 文生视频模型优化得出
在我们找到的三个文生视频模型(Runway Gen-2、Pika Labs 和 Zeroscope)中, Zeroscope 明确提出其由开源模型优化而来。我们认为,这在一定程度上代表了一种 新的技术路线——基于开源,开枝散叶。 ZeroScope 所依托的文本生成视频大模型是阿里达摩院 vilab“Model Scope-damo-textto-video-synthesis”,后者由文本特征提取、文本特征到视频隐空间扩散模型、视频隐 空间到视频视觉空间这 3 个子网络组成,整体模型参数约 17 亿。ZeroScope 由两个组 件构成:Zerscope_v2 567w(用于以较低分辨率快速创建内容)和 Zeroscope_v2 XL (用于将内容升级到高清分辨率)。ZeroScope V3 目前在 Discord 服务器内测试,即将 推出。
3 实测:文生视频模型当前风格各异,总体质量较低
对于文生视频应用,用户主要关注视频生成质量、是否可定制化生成特定内容(如风格、 可对生成内容调整细节等)、使用简易程度等。尽管当前已有可公测的应用,但由于生 成结果粗糙等问题,文生视频并未在实际的媒体内容生成、创意制作领域得到广泛应用。 具体来看,当前可测试的产品风格各异、总体质量较低: Runway Gen-1、Gen-2:是当前文生视频领域实际应用最“出圈”的模型,具 有较好的画面质感,其功能众多,可在文字、图片、视频中自由转化。 ZeroScope:是目前文生视频领域高质量的开源大模型之一。ZeroScope 在 Model Scope 的模型基础上优化而来,能提供更高的分辨率。ZeroScope 可供用户 免费使用,尽管视频分辨率、生成质量与 Runway Gen-2 有一定差距,但其后续潜 力大。 Pika Labs:为近期发布的文生视频平台,该模型一经发布便因其真实感、动作连 续性效果好引发关注。
从生成时间看,当前的文生视频结果时间短,目前 Runway Gen-2 最长可生成 18 秒视 频内容,一般其他可公测使用文生视频模型生成结果均在 4s 左右,且无法融合音频。 从生成平台看,与 Runway、ZeroScope 不同,Pika Labs 采取了与 Midjourney 相同的应 用平台,当前可通过申请在 Discord 端试用(Discord 是一款可进行社群交流的数字发行 平台,用户可发布文字、图片、视频、音频等内容)。
3.1 复杂人物动作生成帧连续效果较差
复杂人物动作的视频生成考验文生视频模型的帧连续效果及动作理解能力。从测试效 果看: RunwayGen2:基本完成文字指令要求,突出“一个女孩”人物主题,跳舞动作 有一定流畅性,但后续出现身体器官重叠问题; Pika Labs:未理解文字指令主题“一个女孩”,出现多个人物,但其舞蹈动作连 续流畅性相对较好; ZeroScope:人物模糊,但身体部位变化自然,且未出现变型、消失等问题。
3.2 非日常场景的视频架构能力连续能力一般
非日常场景的视频生成考验文生视频模型的指令理解及架构能力。从“猫拿遥控器看 电视”这一虚构场景文字指令的要求生成效果看: Runway Gen-2:整体仍然最为出色,但后续动作变化不自然且幅度小,出现脸 部变形等情况; Pika Labs:对文字指令的理解有一定问题,并未体现“拿遥控器”的动作,但其 视频画面细节如毛发、飘动动作更为连贯顺畅; ZeroScope:真实性较强,但动作僵硬且幅度较小。
3.3 多主体视频生成缺乏逻辑连续性
多主体的视频生成考验文生视频模型的复杂场景处理能力及细微语言理解能力。当前 文生视频模型出现直接忽略文字指令中的如“手牵手”,“一个男孩和一个女孩”等细微 要求问题。 Runway Gen-2:对画面及人物动作细节及双人互动如“牵手”指令的处理较好, 生成人物符合逻辑但人物动作幅度不明显; Pika Labs:未体现双人“牵手“细节,但跑步动作自然连贯; ZeroScope:在多人物互动及跑步动作上处理较好,但画面粗糙。
总体来看,三个文生视频模型的不同生成效果体现其背后模型及训练数据特点。 Runway Gen-2:画面精细度、清晰度及艺术美感均较强,视频动作幅度均较小, 视频动感主要体现在如头发的飘动上; Pika Labs:擅于生成连贯动作; ZeroScope:表现较为平均。
4 从图片生成看文生视频的商业前景
4.1 为什么选择图片生成作为对标对象?
4.1.1 图片生成相对成熟
图片生成类在多模态大模型中的商业程度较高,可为视频生成的商业化前景可提供一 定参考。以相对成熟的美国市场为例,据七麦数据 8 月 13 日 IOS 应用榜单,以“AI” 作为搜索关键词,榜内共计 247 个应用,其中“摄影与录像”、“图形与设计”类的图像 生成类应用占比 31.6%;而“音乐”类应用仅占比 2.8%;“效率”类语言生成或对话 式应用占比20.2%。可见图片生成类的商业化程度最高,且从实际案例来看,目前已有 图片生成类应用表现出较强的收费能力。
4.1.2 已经收费的视频生成应用,商业模式与图片生成趋同
目前,从类别上看,图片生成类为现阶段多模态大模型相对成熟的商业化场景,视频 生成类的商业前景可参考图片生成类的商业化发展历程。整体来看,图片生成类的商 业模式较为单一,收费模式和收费依据较为趋同,即按照人工智能生成产品的生成量、 生成速度计算收费,现已出现的视频生成模型的收费依据也与其类似。另外,市场上已 出现个别破圈现象级图片生成类应用,以及与其原有业务协同的 AI 增强功能产品,也 可为未来视频生成类应用的发展提供一定参考。
Runway Gen-2 是文生视频领域最先形成商业模式的多模态大模型案例,其收费标准 为文生视频领域大模型及应用端树立了标杆,与广泛的图片生成类模型及应用的商业 模式类似,Runway Gen-2 也按照生成量、附加权益等区分不同套餐定价。自发布以 来,Runway Gen-2 引起关注度很高,由于是为数不多的开放公测的文生视频大模型, 很多玩家前往其官网进行文生视频的尝试,2023 年 9 月其网站总访问人次为 760 万, 平均停留时长为 3 分 37 秒。
4.2 细分领域:看好人像生成,短期内变现较快
4.2.1 Lensa AI:人像生成功能推出后用户付费意愿高
Lensa AI 切入人像生成领域,新功能推出后收入可观,但是否可若想形成持续性付费 收入仍需探索。Lensa AI App 于 2018 年上线,原本的主要用途是图片编辑和美化。 2022 年 11 月 21 日,Lensa AI 上线的新功能“魔法头像”(Magic Avatars)让其在全球 人气迅速飙升。用户上传人像图,可通过“魔法头像”自动生成各种不同风格的人脸照, 包括摇滚风格、时尚风、科幻风、动漫风等。11 月 30 日至 12 月 14 日,连续两周位列 美国 AppStore 免费榜榜首,还拿下十多个国家的免费榜 Top 1。从商业模式上看,该 应用提供三种不同的购买方案,主要的区别是生成的照片的数量差异。用户可以选 50、 100、200 张照片,分别对应 3.99、5.99、7.99 美元。
根据分析公司 Sensor Tower 的数据,该应用程序在 12 月的前 12 天在全球范围内安装 了约 1350 万次,是 11月 200 万次的六倍多。这 12天消费者在 App上花费了大约 2930 万美元(日流水超百万美元)。根据 Sensor Tower 的最新数据,Lensa AI 在今年 7 月的 全球下载量仅为 40 万人次,同月全球收入仅为 100 万美元。可见人像生成类应用若想 维持热度、形成长期稳定的收费能力,市场玩家仍需继续探索。
4.2.2 妙鸭相机:国内首个“破圈”应用,写真生成引起社交裂变
人像生成写真应用妙鸭相机上架即火爆,迅速爬升社交类应用第一名。妙鸭相机是国 内第一个出圈的图片生成类应用。用户通过上传一张正面照以及不少于 20 张的补充照 片,就能利用妙鸭相机生成各式写真。妙鸭相机收费 9.9 元,可以解锁现有模板,包括 证件照、古装写真、晚礼服写真等。
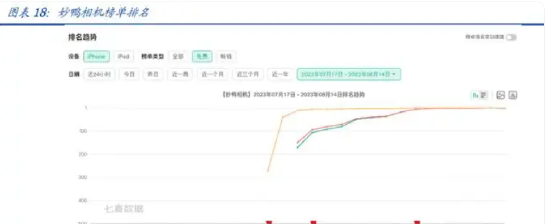
妙鸭相机上线后非常火爆,生成图片的等待时长一路走高,7 月 20 日晚间高峰期有 4000-5000 人排队,需等待十几个小时才能生成图片。据七麦数据,妙鸭相机近自发布 以来,热度高涨,截至 8 月 13 日,妙鸭相机在 iPhone 社交类应用中排名第一。
妙鸭相机现阶段收入规模可观,但市场对其复购及持续收费能力存疑,后续须不停上 线新模板、开创新玩法。据七麦数据,妙鸭相机近自上线以来,半个月时间收入预估总 计超过 29 万美元,近七日日均收入超过 3 万美元,在国内图像生成领域的应用中遥遥 领先,可以算作破圈的现象级产品。但目前还处于拉新阶段,后期用户的复购收入持续 增长的能力亟待验证。
4.3 竞争优势:看好有算力储备的公司
目前,国内外图像生成类模型及模应用大多按照生成量、生成速度等来区分定价,但不 同点是国外产品的付费套餐中多有“无限量”套餐,而国内产品未出现“无限量”套餐, 可看出国内算力仍为瓶颈,因此,具有算力储备的云服务厂商在发展视频生成类应用 时具有天然优势。
4.3.1 Midjourney:“无限量”套餐拢获用户,映射市场对算力的高需求
Midjourney 作为文生图领域的代表性多模态大模型,相比于大多数有限生成量的图片 生成类模型及应用,Midjourney 的“无限量”套餐具有天然优势,其用户规模和营收 已建立起一定壁垒。据 Similar Web 数据,Midjourney 官网在 2023 年 8 月网站访问量 为 2850 万人次,平均停留时长达到 6 分 30 秒。且从市场公开信息得知,Midjourney 的 日活用户已达到 1500 万,超过开源模型 Stable Diffusion 的 1000 万日活,其年营收也 超过 1 亿美元。
4.3.2 腾讯云:云服务厂商加紧多模态生成布局
反过来看,由于本身具有算力能力优势,云服务大厂也开始注重多模态生成的能力建 设,上线图像生成类产品。以腾讯为例,腾讯的 AI 绘画产品作为功能模块,集成在腾 讯云解决方案平台上,客户可选择开通 AI 绘画服务,便可使用此项功能。目前,用户 可在腾讯云上体验“智能文生图”及“智能图生图”功能,两种功能每月共提供 20 次 体验额度,正式服务需接入 API 使用。腾讯云 AI 绘画功能分为 PaaS 和 SaaS 两种产品 形态,PaaS 需要二次开发,SaaS 版开箱即用。
4.3.3 无界 AI:“按时长付费”和“潮汐生成模式”彰显算力底座特性
无界 AI 于 2022 年 5 月入局 AI 绘画,为国内较早起步的 AI 作画工具平台之一。用户可 通过直接开通会员享受基本权益,价格为100元/月、1000元/年,能实现文生图,选择 画面大小、主题、风格等元素,还享有潮汐模式免费无限创作、解锁全部专用模型、存 储无限扩容、精绘折扣、选择更多参数等会员权益。其中,潮汐模式下会员可以免费无 限创作。“潮汐模式”由夜间生成更便宜的“夜间生成模式”发展而来,旨在利用算力 资源空闲时段作画,实现“以时间换价格”。 用户还可开通权益卡或购买时长。其中,1)开通权益卡能获得更多积分,适用于对普 通文生图有更多需求(如更多超分辨次数、更多单张加速次数)的用户。2)购买时长 适用于需要更多生成类型(如图生图、条件生图)和功能(如局部重绘、多区域控制绘 图等)的用户,即专业版用户。按时长付费也是阿里云、腾讯云等 AI 云算力服务商常 用的收费方式,我们认为,这在一定程度上,反映出 AI 图片生成应用与底层算力服务 的高度相关性。
4.4 业务协同:看好多模态生成与原有业务有协同的公司
4.4.1 Adobe :AI 生成工具有望带来增量付费用户
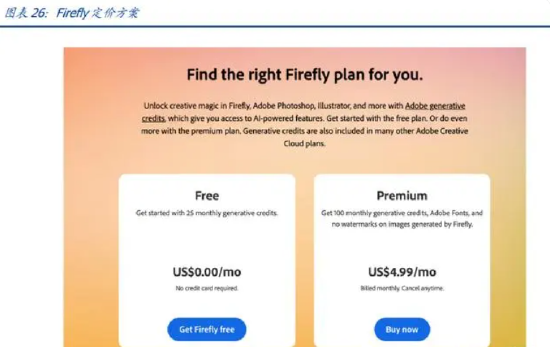
Adobe 上线 AI 创意生成工具 Firefly(萤火虫),或为 Adobe 带来增量付费用户。 Photoshop 于 2023 年 3 月发布 AI 创意生成工具 Firefly,具有文生图及图像填充功能, 并且于 5 月底宣布全面开放,深度绑定 Adobe 旗下产品 Photoshop。
Adobe于2023年9月13日宣布Firefly正式商用,将采取按生成点数(Generativecredits) 收费的模式,每个点数对应一张图片。其中,免费账户每月享有 25 生成点数,升级版 用户每月支付 4.99 美元即可享有 100 积分。根据 Adobe 官网,Firefly 自 2023 年 11 月 1 日起将实行限额,生成积分的消耗取决于生成输出的计算成本和所使用的生成人 工智能功能的价值。
4.4.2 Microsoft 365 Copilot:推出增强功能,高定价反应市场强需求
Microsoft 365 Copilot 定价策略大幅超预期,侧面反应人工智能生成产品的强劲需求。 Office Copilot 是基于 GPT-4 API 的应用,具有文档编辑、表格处理等在 Office 软件原有 基础上利用 AI 开发的增强功能。7 月 18 日,微软在合作伙伴会议上宣布 Microsoft 365 Copilot 定价策略,Microsoft 365Copilot 将面向 Microsoft 365 E3、E5、Business Standard 和 Business Premium 客户的商业客户提供,价格为每用户 30 美元/月,大超 发布前的市场预期。此前 Microsoft 365 商业版定价最高为 22 美元/月,按照当前四种 商业版的订阅价格计算,Copilot 加入后整体订阅价格涨幅约在 53-240%。此次 Copilot 的定价反映了微软对其新产品的信心以及市场对 AI 增强功能的强需求。
4.5 展望:看好文生视频与文生图、图生视频的联动
由于当前文生图、文生视频、文生音频等都具有一定局限性,已经有创作者借助不同 模型平台进行视频合成,从而实现最优效果。例如,近日出现的一则约一分钟左右完 全由 AI 生成的科幻预告片《Trailer: Genesis》(创世纪),其中用到了 Midjourney 处理 图像、Runway 处理视频、Pixabay 处理音乐、CapCut 剪辑视频。我们预计,后续 AI 在 文生图、文生视频、文生音频及剪辑等方面的应用仍有很大的发展空间,其对于生产力 的释放值得期待。

0