
关于作者
曹煊博士系腾讯优图实验室高级研究员。优图— 腾讯旗下顶级的机器学习研发团队,专注于图像处理、模式识别、深度学习。在人脸识别、图像识别、医疗AI、OCR、哼唱识别、语音合成等领域都积累了领先的技术水平和完整解决方案。
《Mars说光场》系列文章目前已有5篇,包括:
《Mars说光场(1)— 为何巨头纷纷布局光场技术》;
摘要 — 光场(Light Field)是空间中光线集合的完备表示,采集并显示光场就能在视觉上重现真实世界。全光函数(Plenoptic Function)包含7个维度,是表示光场的数学模型。光场是以人眼为中心对光线集合进行描述。由于光路是可逆的,以发光表面为中心来描述光线集合衍生出与光场类似的概念——反射场(Reflectance Field)。反射场也具有7个维度的信息,但每个维度的定义与光场不尽相同。不论光场还是反射场,由于7个维度的信息会急剧增加采集、处理、传输的负担,因此实际应用中更多的是采用4D光场模型。随着Magic Leap One的上市,以及Google《Welcome to light field》在Steam上发布,光场作为下一代成像/呈像技术,受到越来越多的关注。本文将详细介绍光场的基本概念,尤其是4D光场成像相比传统成像的优势。
1、什么是光场?
在人类的五大感知途径中,视觉占据了70%~80%的信息来源;而大脑有大约50%的能力都用于处理视觉信息[]。借助视觉,我们能准确抓取杯子,能在行走中快速躲避障碍物,能自如地驾驶汽车,能完成复杂的装配工作。从日常行为到复杂操作都高度依赖于我们的视觉感知。然而,现有的图像采集和显示丢失了多个维度的视觉信息。这迫使我们只能用二维“窗口”去观察三维世界。例如医生借助单摄像头内窥镜进行腹腔手术时,因无法判断肿瘤的深度位置,从而需要从多个角度多次观察才能缓慢地下刀切割。再例如远程机械操作人员通过观看监视器平面图像进行机械遥控操作时,操作的准确性和效率都远远低于现场操作。
人眼能看见三维世界是因为人眼接收了物体发出的光线(主动或被动发光),而光场就是三维世界中光线集合的完备表示。“Light Field”这一术语最早出现在Alexander Gershun于1936年在莫斯科发表的一篇经典文章中,后来由美国MIT的Parry Moon和Gregory Timoshenko在1939年翻译为英文[]。但Gershun提出的“光场”概念主要是指空间中光辐射可以表示为关于空间位置的三维向量,这与当前“计算成像”、“裸眼3D”等技术中提及的光场不是同一个概念。学术界普遍认为Parry Moon在1981年提出的“Photic Field”[]才是当前学术界所研究的“光场”。 随后,光场技术得到了一些顶级研究机构的关注,其理论逐步得到完善,多位相关领域学者著书立作逐步将光场技术形成统一的理论体系,尤其是在光场的采集[]和3D显示[,]两个方面。欧美等高校开设了专门的课程——计算摄像学(Computational Photography)。
如图1所示,人眼位于三维世界中不同的位置进行观察所看到的图像不同,用(x, y, z)表示人眼在三维空间中的位置坐标。光线可以从不同的角度进入人眼,用(a, b)表示进入人眼光线的水平夹角和垂直夹角。每条光线具有不同的颜色和亮度,可以用光线的波长(r)来统一表示。进入人眼的光线随着时间(t)的推移会发生变化。因此三维世界中的光线可以表示为7个维度的全光函数(Plenoptic Function, Plen-前缀具有“全能的、万金油”的意思)[]。
P(x, y, z, a, b, r, t)
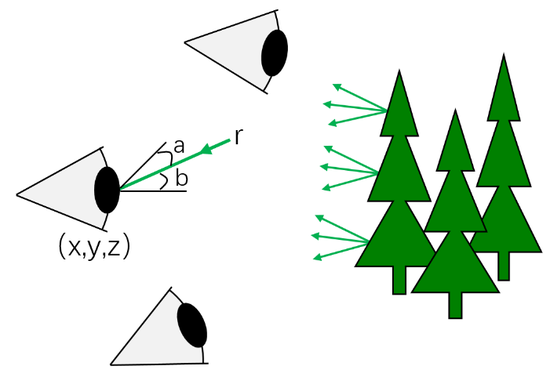
图1。 7D全光函数示意图
上述光场的描述是以人眼为中心。光路是可逆的,因此光场也可以以物体为中心等效的描述。与“光场”相类似的另一个概念是“反射场(Reflectance Field)”。如图2所示,物体表面发光点的位置可以用(x, y, z)三个维度来表示;对于物体表面的一个发光点,总是向180度半球范围内发光,其发光方向可以用水平角度和垂直角度(a, b)来表示;发出光线的波长表示为(r);物体表面的光线随着时间(t)的推移会发生变化。同理,反射场可以等效表示为7维全光函数,但其中的维度却表示不同的意义。
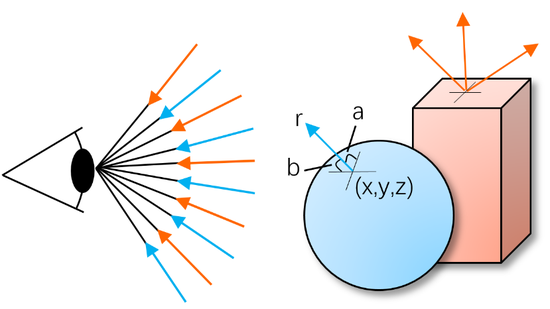
图2。 7D反射场示意图
对比全光函数与反射场可以发现:全光函数与反射场都可以用7个维度来表征,全光函数是以人眼为中心描述空间中所有的光线,反射场是以物体表面发光点为中心描述空间中所有的光线。全光函数所描述的光线集合与反射场所描述的光线集合是完全一致的。换句话说,全光函数中的任一条光线都可以在反射场中找到。
2、为什么要研究光场?
以自动驾驶为例,首先需要通过多种传感器去“感知”外界信息,然后通过类脑运算进行“决策”,最后将决策以机械结构为载体进行“执行”。现阶段人工智能的发展更倾向于“类脑”的研究,即如何使计算机具有人脑类似的决策能力。然而却忽略了“眼睛”作为一种信息感知入口的重要性。设想一个人非常“聪明”但是视力有障碍,那么他将无法自如的驾驶汽车。而自动驾驶正面临着类似的问题。如果摄像机能采集到7个维度所有的信息,那么就能保证视觉输入信息的完备性,而“聪明”的大脑才有可能发挥到极致水平。然而,不幸是的目前市面上绝大多数成像设备都不能采集7D光场,只能采集其中部分维度信息。
从1826全世界第一台相机诞生[]至今已经有近两百年历史,但其成像原理仍然没有摆脱小孔成像模型。在介绍小孔成像模型之前,先看看如果直接用成像传感器(e.g。 CCD)采集图像会发生什么事呢? 如图3所示,物体表面A、B、C三点都在向半球180度范围内发出光线,对于CCD上的感光像素A‘会同时接收到来自A、B、C三点的光线,因此A’点的像素值近似为物体表面上A、B、C三点的平均值。类似的情况也会发生在CCD上的B‘和C’点的像素。因此,如果把相机上的镜头去掉,那么拍摄的图片将是噪声图像。
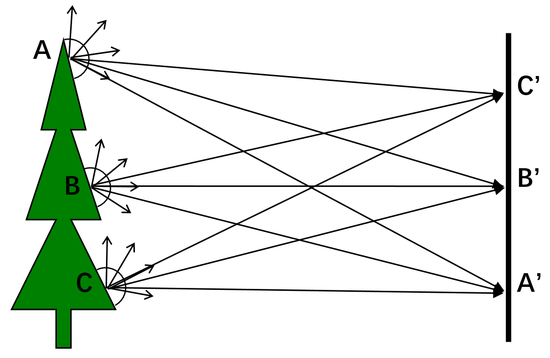
图3 无小孔的噪声成像
如果在CCD之前加一个小孔,那么就能正常成像了,如图4所示。CCD上A‘点只接收到来自物体表面A点的光线。类似的,CCD上B’和C‘点也相应只接收到物体表面B点和C的点光线。因此,在CCD上可以成倒立的像。
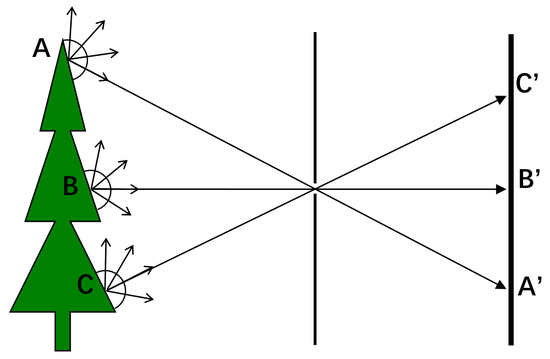
图4。 小孔成像
实际的相机并没有采用如图4中的理想小孔成像模型,因为小孔直径较小会导致通光亮非常小,信噪比非常低,成像传感器无法采集到有效的信号;如果小孔直径足够小,当与光波长相当时还会产生衍射现象。而小孔直径过大会导致成像模糊。现代的成像设备用透镜来替代小孔,从而既能保证足够的通光量,又避免了成像模糊。如图5所示,物体表面A点在一定角度范围内发出的光线经过透镜聚焦在成像传感器A’点,并对该角度范围内所有光线进行积分,积分结果作为A点像素值。这大大增加了成像的信噪比,但同时也将A点在该角度范围内各方向的光线耦合在一起。
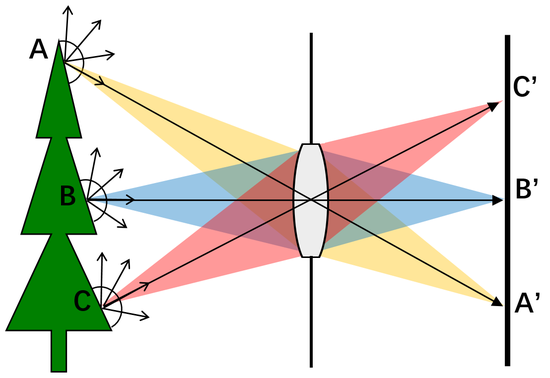
图5。 透镜小孔成像
小孔成像模型是光场成像的一种降维形式,只采集了(x, y, r, t)四个维度的信息。RGB-D相机多了一个维度信息(x, y, z, r, t)。相比全光函数,其主要丢失的维度信息是光线的方向信息(a, b)。缺失的维度信息造成了现在成像设备普遍存在的一系列问题。在图像采集方面,可以通过调节焦距来选择聚焦平面,然而无论如何调节都只能确保一个平面清晰成像,而太近或太远的物体都会成像模糊,这给大场景下的识别任务造成了极度的挑战。在渲染显示方面,由于(a, b)维度信息的缺失会引起渲染物体缺乏各向异性的光线,从而显得不够逼真。好莱坞电影大片中渲染的逼真人物大多采用了光场/反射场这一技术才得以使得各种科幻的飞禽走兽能栩栩如生。
3、光场4D参数化
根据7D全光函数的描述,如果有一个体积可以忽略不计的小球能够记录从不同角度穿过该小球的所有光线的波长,把该小球放置在某个有限空间中所有可以达到的位置并记录光线波长,那么就可以得到这个有限空间中某一时刻所有光线的集合。可惜,目前全世界还没有这样的理想小球。即使有类似的采集设备,但采集的数据量也非常巨大。按照当前的计算机技术水平,这么庞大的数据难以处理和传输。因此有必要对7D全光函数进行简化降维。
如图6所示,美国斯坦福大学的Marc Levoy将全光函数简化降维,提出(u,v,s,t)4D光场模型[]。Levoy假设了两个不共面的平面(u,v)和(s,t),如果一条光线与这两个平面各有一个交点,则该光线可以用这两个交点唯一表示。Levoy提出的光场4D模型有一个重要的前提假设:在沿光线传播方向上的任意位置采集到的光线是一样的。换句话说,假设任意一条光线在传播的过程中光强不发生衰减且波长不变。考虑到日常生活中光线从场景表面到人眼的传播距离非常有限,光线在空气中的衰减微乎其微,上述Levoy提出的假设完全合理。
Levoy提出的光场4D模型并不能完备地描述三维空间中所有的光线,与(u,v)或(s,t)平面所平行的光线就不能被该4D模型所表示,例如图6中红色标示的光线。尽管Levoy提出的4D模型不能用于完备描述三维空间中所有的光线,但可以完备描述人眼接收到的光线。因为当光线与人眼前视方向垂直时,该光线不会进入人眼。因此,这部分光线并不影响人眼视觉成像。Levoy提出的4D模型既降低了表示光场所需的维度,同时又能完备表示人眼成像所需要的全部光线。光场4D模型得到了学术界的广泛认可,关于光场的大量研究都是在此基础上展开。

图6。 4D光场模型
4D光场模型具有可逆性,既能表示光场采集,又能表示光场显示。如图7所示,对于光场采集模型,右侧物体发出的光线经过(s,t)和(u,v)平面的4D参数化表示,被记录成4D光场。对于光场显示模型,经过(u,v)和(s,t)平面的调制可以模拟出左侧物体表面的光线,从而使人眼“看见”并不存在的物体。
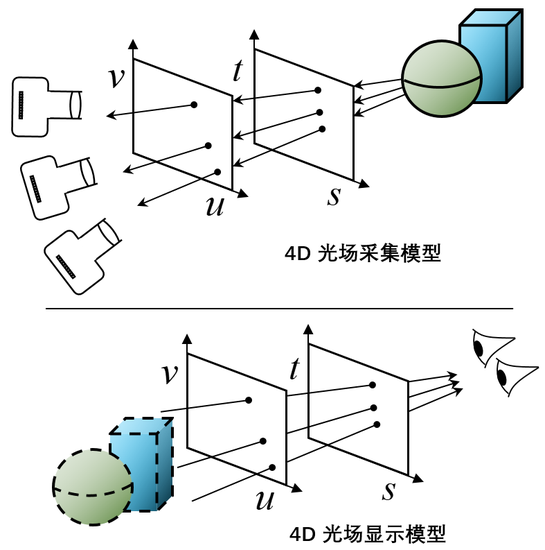
图 7。 4D光场模型的可逆性
如图8所示,物体表面A、B、C三点发出的光线首先到达(u,v)平面,假设(u,v)平面上有三个小孔h1、h2、h3,则A、B、C三点发出的光线经三个小孔分别到达(s,t)平面。A、B、C三点在半球范围内三个不同方向的光线被同时记录下来,例如A点三个方向的光线分别被(s,t)平面上A3’、B3’、C3’记录。如果(u,v)平面上小孔数量更多,且(s,t)平面上的像素足够密集,则可以采集到空间中更多方向的光线。需要说明的是,图8中展示的是(u,v)(s,t)光场采集模型在垂直方向上的切面图,实际上可以采集到A、B、C三点9个不同方向(3x3)的光线。
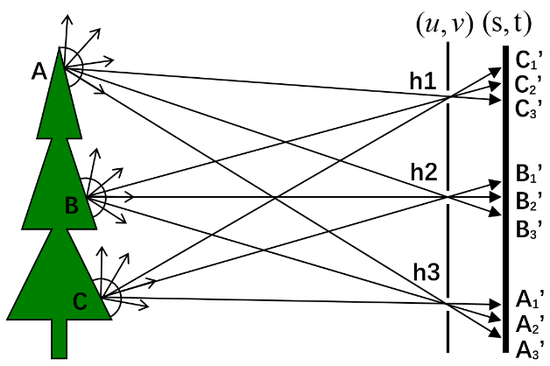
图8。 4D光场采集空间光线示意图
图像分辨率和FOV(Field Of View)是传统相机成像性能的主要指标。衡量4D光场的指标不仅有图像分辨率和FOV,还有角度分辨率和FOP。 图9展示了基于微透镜阵列的光场相机的光路示意图,物体表面发出的光线进入相机光圈,然后被解耦和并分别被记录下来。以B点为例,发光点B在半球范围内发出各向异性的光线,但并不是所有的光线都进入相机光圈,只有一定角度内的光线被成功采集,被光场相机采集到的光线的角度范围决定了能够观察的最大视差范围,我们记这个角度为FOP(Field Of Parallax)。换句话说,图9中光场相机只能采集到B点FOP角度范围内的光线。但FOP的大小随着发光点与光场相机的距离远近而不同,因此通常采用基线的长度来衡量FOP的大小,图9中主镜头的光圈直径即为基线长度。
图9中B点在FOP角度范围内的光线被微透镜分成4x4束光线,光场相机的角度分辨率即为4x4,光场相机的角度分辨率表征了一个发光点在FOP角度范围内的光线被离散化的程度。而基于小孔成像模型相机的角度分辨率始终为1x1。光场的视点图像分辨率同样表征了被采集场景表面离散化程度,成像传感器分辨率除以角度分辨率即为视点图像分辨率。
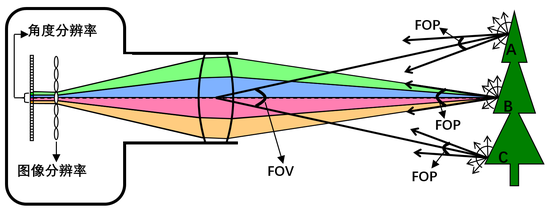
图8。 透镜阵列4D光场的图像分辨率和角度分辨率
基于相机阵列的光场相机同样可以用视点图像分辨率、角度分辨率、FOV、FOP四个参数来衡量光场相机的各方面性能。如图9所示为4x4相机阵列,B点半球范围内发出的光线中FOP角度范围内的光线被相机阵列分成4x4束并分别被采集。相机的个数4x4即为角度分辨率,单个相机成像传感器的分辨率即为视点图像分辨率。所有相机FOV的交集可以等效为光场相机的FOV。基于相机阵列的光场相机的基线长度为两端相机光心之间的距离。一般而言,基于相机阵列的光场相机比基于微透镜阵列的光场相机具有更长的基线,也就具有更大的FOP角度。
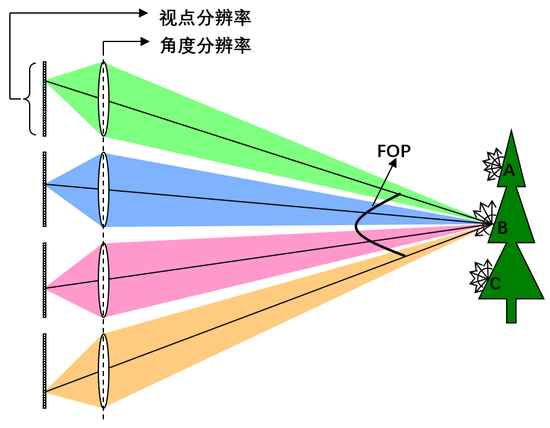
图9。 相机阵列4D光场的图像分辨率和角度分辨率
4、光场4D可视化
4D光场数据可以表示为(Vx, Vy, Rx, Ry),其中(Vx, Vy)表征了角度分辨率,表示有Vx*Vy个视点(View)图像;(Rx, Ry)表征视点图像分辨率,表示单个视点图像的分辨率为Rx*Ry。如图10中上侧图展示了7x7光场的可视化,表示共有49个视点图像,每个视点的图像分辨率为384x512。视点图像分辨率越高,包含的细节越多。角度分辨率越高,单位角度内视点数量越多,视差过度越平滑。当可视角度一定时,角度分辨率越低,视点越稀疏,观看光场时视点跳跃感越明显;角度分辨率越高,视点越稠密,观看光场时视点越连续。假设在10度的可视角度内水平方向上包含了7个视点,相邻视点间的角度为1.67度,在2米的观看距离,相邻两个视点的水平距离为29毫米。当视点个数减少,相邻视点的空间距离变大,观看者移动观看位置时就会感到明显的视点跳跃。
光场中任意两个视点间都存在视差,将光场(Vx, Vy, Rx, Ry)中的部分视点图像放大,如图10中下侧所示;同一行所有视点图像之间只有水平视差,没有垂直视差;同一列所有视点图像之间只有垂直视差,没有水平视差。

图 10。 光场角度分辨率和视点分辨率可视化分析
光场作为高维数据,不便于可视化分析。为了更好的分析光场中的视差,可以将光场中某一个水平视点上所有图像的同一行像素堆成一幅2D图像,称之为光场切片数据(Light Field Slice)。光场切片图像可以将光场中的水平视差和垂直视差可视化,便于直观分析。如图11中蓝色线条所在的行像素堆叠后就形成了图11中下侧的光场切片图像。类似的,如图11中将光场中同一垂直视点上所有绿色线条所在的列像素堆叠后就形成了图11中右侧的光场切片图像。

图11。 光场切片图例
5、光场技术展望
从全世界光场技术的发展趋势来看,美国硅谷的科技巨头争相布局和储备光场技术,有些甚至已经出现了Demo应用。在光场的采集方面,例如Google在Steam平台上发布的《Welcome to Light Field》、Lytro光场相机。在光场显示方面,例如Magic Leap采用的两层离散光场显示技术、NVIDIA发布的近眼光场显示眼镜、Facebook旗下Oculus的道格拉斯•兰曼团队正在研发的光场VR头盔。
光场技术的研究主要分为两大方面,包括光场采集和光场显示。光场采集技术相对更成熟,在某些To B领域已经基本达到可以落地使用的程度。光场采集主要是提供3D数字内容,一次采集可以推广使用,这并不要求由个体消费者来完成,一般都是由一个团队来完成。因此对于光场采集系统的硬件成本、体积、功耗有更大的可接受度。相比之下,光场显示是偏向To C的产品,个体用户在成本、体积、功耗、舒适度等多方面都极度挑剔。光场显示在多个高校和科研机构已经完成了原形样机的开发,在通往商业化实用的道路上,目前最大的挑战就在于光场显示设备的小型化和低功耗。
Magic Leap One的推出似乎并没有达到消费者原本对它的期待,这其中的差距是可以解释的。是否具备光场显示对于VR/AR头盔来说最大的区别是能否解决VAC (Vergence–Accommodation Conflicts) 问题,关于VAC的解释具体可参见《Mars说光场(2)— 光场与人眼立体成像机理》。当前的VR/AR头盔只有一层呈像平面,会引起头晕、近视等VAC问题。当光场VR/AR头盔中呈现无穷多层不同距离上的呈像平面时,VAC的问题就会得到完美解决。然而在可预见的未来,实现无穷多层呈像平面的光场显示技术是不现实的。换句话说,在可预见的未来,让个体消费者能使用上完美理想的光场显示设备,这本来就是一个不切实际的目标。因此只能尽量增加光场中呈像平面的层数,VAC的问题随着层数的增加就会得到越明显的改善。
在Magic Leap One上市之前,所有商业化的显示设备都是在追求分辨率、色彩还原度等指标的提升,而从来没有显示维度的突破。Magic Leap One是目前全世界范围内第一款具有大于1层呈像平面的商业化头戴显示设备。Magic Leap One的2层呈像平面相比HoloLens的1层呈像平面在视觉体验上并不会带来明显的改善,但是在对长期佩戴所引起的疲劳、不适、近视等问题是会有所改善的。然而用户对此并不买账,可以解释为三方面的原因:(1)目前VR/AR设备的用户使用时间本来就很短,用户对于缓解疲劳等隐性的改善没有直观立即的体验,这些隐性的改善往往会被忽略。(2)现代消费人群没有体验过黑白电视和CRT显示器,在新兴消费人群中1080P、全彩色、无色差等是他们对显示设备的底线要求,而且这种底线还在逐年提高。当Magic Leap One上市时,一旦分辨率或色彩还原度低于消费者能接受的底线,纵然光场带来了其他的隐性改善,但消费者会在第一印象中产生抗拒情绪。相比手机的高质量显示,Magic Leap One和HoloLens在显示的质量上都有所退化,对于已经习惯2K的用户而言,很难接受这样的显示质量退化。(3)Magic Leap One的呈像平面从1层增加到2层,这并代表其视觉体验就能改善2倍。只有当呈像平面达到一定数量以后,人眼才能感觉到视觉呈像质量的明显改善。
尽管Magic Leap的2层光场显示并没有得到用户的高度认可,但它在显示的维度上实现了0到1的突破。光场显示层数从单层增加到2层,这是光场显示技术商业化的良好开端,后续从2层增加到10层甚至20层只是时间的问题了。回顾手机发展历史,手机显示经历了从大哥大时代的单行黑白屏到现在iPhone X约2K全彩显示屏。我相信目前光场显示设备就像30年前的大哥大一样,正处于黎明前的黑暗,必然还需要经历多次的进化。一旦成功,其最终光场显示的效果相对目前的智能手机来说将会是革命性的进步。
来源于:雷锋网
原文链接:https://www.leiphone.com/news/201810/N14i2K6UmZzK5TcE.html
作者:腾讯科技高级研究员 曹煊博士
本文转自雷锋网,如需转载请至雷锋网官网申请授权。
0