
近日,Meta 公开一个新的开源人工智能模型ImageBind,该模型能够将六种类型的数据整合在一起,包括视觉(以图像和视频形式呈现);热量(红外图像);文本;音频;深度信息;以及最有趣的——由惯性测量单元(IMU)生成的运动读数。
该模型目前只是研究项目,还没有直接的消费者或实际应用,但它展示了未来生成式人工智能系统的可能性,这些系统能创造出沉浸式、多感官的体验。
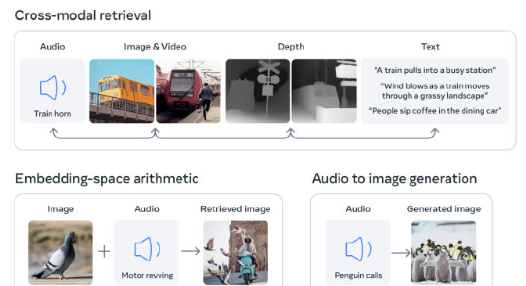
同时,该模型也表明了 Meta 公司在人工智能研究领域的开放态度,而其竞争对手如 OpenAI 和谷歌则变得越来越封闭。

新浪声明:新浪网登载此文出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。
0